At SuperAwesome, we build technology that makes the internet safer for kids. Every month, we handle requests from hundreds of millions of kids located all around the world. These kids use their devices moderately in the morning, a little bit during the day, and a lot in the evening. As a result, we had to build highly scalable systems that would respond automatically to that demand.
This post explains how horizontal auto-scaling can be achieved using the tools offered by Kubernetes and its ecosystem (and won’t cover other kinds of auto-scalers like the Vertical Pod Autoscaler).
Why auto-scaling?
Auto-scaling is a method that allows you to automatically create and destroy your resources (servers, containers, anything else you might need) based on different automated rules.
Without auto-scaling, you would need to create resources to handle the peak traffic that you would receive during the day. With auto-scaling, you can create these resources when they are needed, and delete them when they are idle. This could potentially save you (a lot of) money.
If your application is stateless (and it should be whenever possible), you will want to scale horizontally.

Scaling pods
The resources that you deal with inside Kubernetes are Pods. Stateless applications are usually deployed using Deployments. To scale the number of pods in a deployment, you will need to create a Horizontal Pod Autoscaler (HPA).
The easiest metric to scale on is the CPU usage of your pods.

As the load on your application increases, so will the average CPU usage. Whenever it crosses the auto-scaling threshold, Kubernetes will add new pods to your deployment. These new pods will lower the average CPU usage and bringing it back under the auto-scaling threshold.

The Horizontal Pod Autoscaler Walkthrough is a good place to get started.
Scaling nodes
Scaling the pods is not enough to save resources, you will also need to add/remove Kubernetes nodes dynamically using a cluster auto-scaler.
The official cluster auto-scaler is reactive – it will add nodes to the cluster only when pods can’t be scheduled:
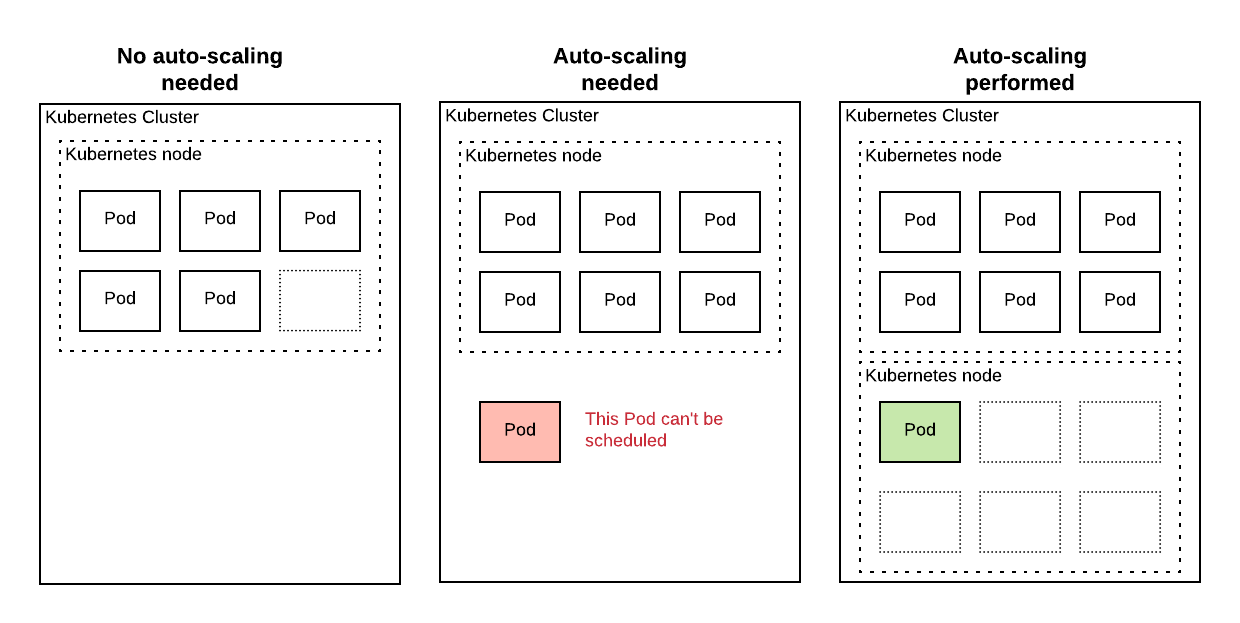
If there is enough free space on your cluster, it will remove one of the underutilized nodes and it will reschedule its pods on the other nodes:

To scale down without downtime, don’t forget to set the minimum number of replicas on your Horizontal Pod Autoscaler to 2 and to set some anti-affinity rules.

Scaling pods using custom metrics
Scaling pods based on CPU is easy but not always effective. For example, you might want to scale based on the number of requests received by your application (to avoid high response times even if the CPU usage is low), the number of messages in a queue (to process them within a certain amount of time), or the time of day (to anticipate a predictable sudden increase in traffic). To do so, you will need to collect these custom metrics and expose them to the Horizontal Pod Autoscaler (HPA).

You can achieve this with different tools. For example, Prometheus, Datadog or StackDriver. Here is how the HPA will scale your deployment:
- The pods will push metrics to a metrics collector (Datadog), or the metrics collector will scrape them from the pods (Prometheus, StackDriver, Datadog). Even if you are not using Prometheus, expose them using the Prometheus format to decouple your code from your monitoring system.
- The metrics collector will then send these metrics to a metrics server. It can be external (StackDriver, Datadog) or deployed on your cluster (Prometheus).
- The HPA will then request the metrics to the custom metrics API.
- The custom metrics API will call the custom metrics adapter registered on the cluster.
- The adapter will fetch the metrics and return them.
- The HPA will then decide if the number of pods needs to be changed and update the deployment accordingly.
I hope that this will help you with your own auto-scaling journey. We are always looking for passionate software engineers to help us make the internet safer for kids. If it is something you care about, don’t hesitate to reach out.
(If you’re interested in staying on top of technology and kidtech news, we publish several kids industry newsletters which now have over 10k subscribers reading monthly. Sign up now!)
Nicolas Trésegnie is Chief Architect at SuperAwesome.
